Διαφήμιση
Πιστεύετε στην ιδέα ότι μόλις δημοσιευτεί κάτι στο Διαδίκτυο, δημοσιεύεται για πάντα; Λοιπόν, σήμερα θα διαλύσουμε αυτόν τον μύθο.
Η αλήθεια είναι ότι σε πολλές περιπτώσεις είναι πολύ πιθανό να εξαλειφθούν οι πληροφορίες από το Διαδίκτυο. Σίγουρα, υπάρχει μια εγγραφή ιστοσελίδων που έχουν διαγραφεί εάν κάνετε αναζήτηση στο Μηχανή Wayback, σωστά? Ναι, απολύτως. Στο Wayback Machine υπάρχουν εγγραφές ιστοσελίδων που χρονολογούνται εδώ και πολλά χρόνια - σελίδες που δεν θα βρείτε με μια αναζήτηση Google επειδή η ιστοσελίδα δεν υπάρχει πλέον. Κάποιος το διέγραψε ή ο ιστότοπος τερματίστηκε.
Λοιπόν, δεν υπάρχει πρόβλημα, σωστά; Οι πληροφορίες θα χαράσσονται για πάντα στην πέτρα του Διαδικτύου, εκεί για γενιές να δουν; Λοιπόν, όχι ακριβώς.
Η αλήθεια είναι ότι ενώ μπορεί να είναι δύσκολο ή αδύνατο να εξαλειφθούν σημαντικές ειδήσεις που έχουν πολλαπλασιαστεί από έναν ιστότοπο ειδήσεων ή ιστολόγιο σε άλλο σαν ιός, είναι πραγματικά πολύ εύκολο να εξαλείψετε εντελώς μια ιστοσελίδα ή πολλές ιστοσελίδες από όλα τα αρχεία ύπαρξης - να αφαιρέσετε αυτήν τη σελίδα τόσο για τις μηχανές αναζήτησης όσο και ο
Μηχανή Wayback Το νέο μηχάνημα Wayback σάς επιτρέπει να ταξιδεύετε οπτικά στον χρόνο του ΔιαδικτύουΦαίνεται ότι μετά την κυκλοφορία του Wayback Machine το 2001, οι ιδιοκτήτες του ιστότοπου αποφάσισαν να πετάξουν το back-end που βασίζεται στην Alexa και να τον επανασχεδιάσουν με τον δικό τους κώδικα ανοιχτού κώδικα. Μετά τη διεξαγωγή δοκιμών με ... Διαβάστε περισσότερα . Υπάρχει βέβαια μια σύλληψη, αλλά θα φτάσουμε σε αυτό.3 τρόποι κατάργησης σελίδων ιστολογίου από το Διαδίκτυο
Η πρώτη μέθοδος είναι αυτή που χρησιμοποιούν οι περισσότεροι κάτοχοι ιστότοπων, επειδή δεν γνωρίζουν καλύτερα - απλώς τη διαγραφή ιστοσελίδων. Αυτό μπορεί να συμβεί επειδή έχετε συνειδητοποιήσει ότι έχετε διπλό περιεχόμενο στον ιστότοπό σας ή επειδή έχετε μια σελίδα που δεν θέλετε να εμφανίζεται στα αποτελέσματα αναζήτησης.
Απλώς διαγράψτε τη σελίδα
Το πρόβλημα με την πλήρη διαγραφή σελίδων από τον ιστότοπό σας είναι ότι αφού έχετε ήδη δημιουργήσει τη σελίδα στο net, είναι πιθανό να υπάρχουν σύνδεσμοι από τον ιστότοπό σας, καθώς και εξωτερικοί σύνδεσμοι από άλλους ιστότοπους προς το συγκεκριμένο σελίδα. Όταν τη διαγράφετε, η Google αναγνωρίζει αμέσως τη σελίδα σας ως σελίδα που λείπει.
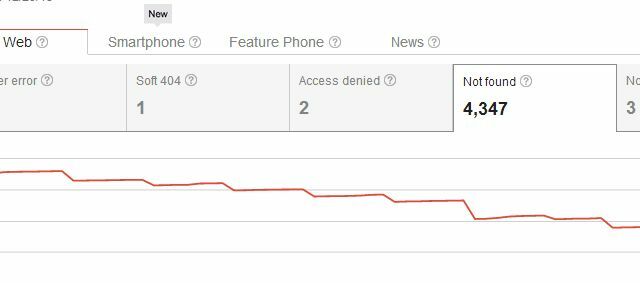
Έτσι, κατά τη διαγραφή της σελίδας σας, δεν έχετε δημιουργήσει μόνο ένα πρόβλημα με τα σφάλματα ανίχνευσης "Δεν βρέθηκαν" για εσάς, αλλά έχετε δημιουργήσει επίσης ένα πρόβλημα για όποιον συνδέθηκε ποτέ με τη σελίδα. Συνήθως, οι χρήστες που μεταβαίνουν στον ιστότοπό σας από έναν από αυτούς τους εξωτερικούς συνδέσμους θα βλέπουν τη σελίδα 404, η οποία δεν είναι σημαντικό πρόβλημα, εάν χρησιμοποιείτε κάτι όπως τον προσαρμοσμένο κωδικό 404 της Google για να δώσετε στους χρήστες χρήσιμες προτάσεις ή εναλλακτικές λύσεις. Ωστόσο, πιστεύετε ότι θα μπορούσαν να υπάρχουν πιο χαριτωμένοι τρόποι διαγραφής σελίδων από τα αποτελέσματα αναζήτησης χωρίς να ξεκινούν όλες αυτές τις 404 για υπάρχοντες εισερχόμενους συνδέσμους, σωστά;
Λοιπόν, υπάρχουν.
Κατάργηση σελίδας από τα αποτελέσματα αναζήτησης Google
Πρώτα απ 'όλα, πρέπει να καταλάβετε ότι εάν η ιστοσελίδα που θέλετε να καταργήσετε από τα αποτελέσματα αναζήτησης Google δεν είναι σελίδα από τον δικό σας ιστότοπο, τότε δεν είστε τυχεροί, εκτός εάν υπάρχουν νομικοί λόγοι ή εάν ο ιστότοπος έχει δημοσιεύσει τα προσωπικά σας στοιχεία στο διαδίκτυο χωρίς τα δικά σας άδεια. Εάν συμβαίνει αυτό, χρησιμοποιήστε το Google εργαλείο αντιμετώπισης προβλημάτων κατάργησης για να υποβάλετε αίτημα για κατάργηση της σελίδας από τα αποτελέσματα αναζήτησης. Εάν έχετε μια έγκυρη περίπτωση, μπορεί να βρείτε κάποια επιτυχία με την κατάργηση της σελίδας - φυσικά μπορεί να έχετε ακόμη μεγαλύτερη επιτυχία επικοινωνία με τον κάτοχο του ιστότοπου Πώς να αφαιρέσετε ψεύτικες προσωπικές πληροφορίες στο ΔιαδίκτυοΤο διαδικτυακό απόρρητο δεν είναι πλέον εγγυημένο. Μάθετε πώς μπορείτε να αναφέρετε έναν ιστότοπο και να καταργήσετε προσωπικά στοιχεία από το Διαδίκτυο. Διαβάστε περισσότερα όπως περιέγραψα πώς να κάνω το 2009.
Τώρα, εάν η σελίδα που θέλετε να καταργήσετε από τα αποτελέσματα αναζήτησης βρίσκεται στον ιστότοπό σας, είστε τυχεροί. Το μόνο που χρειάζεται να κάνετε είναι να δημιουργήσετε ένα robots.txt αρχειοθετήστε και βεβαιωθείτε ότι έχετε απαγορεύσει είτε τη συγκεκριμένη σελίδα που δεν θέλετε στα αποτελέσματα αναζήτησης είτε ολόκληρο τον κατάλογο με τα περιεχόμενα που δεν θέλετε να ευρετηριαστούν. Δείτε πώς φαίνεται ο αποκλεισμός μίας σελίδας.
Αντιπρόσωπος χρήστη: * Απαγόρευση: /my-deleted-article-that-i-want-removed.html
Μπορείτε να αποκλείσετε τα bots από την ανίχνευση ολόκληρων καταλόγων του ιστότοπού σας ως εξής.
Αντιπρόσωπος χρήστη: * Απαγόρευση: / content-about-personal-stuff /
Το Google έχει μια εξαιρετική σελίδα υποστήριξης που μπορεί να σας βοηθήσει να δημιουργήσετε ένα αρχείο robots.txt εάν δεν το έχετε δημιουργήσει ποτέ πριν. Αυτό λειτουργεί εξαιρετικά καλά, όπως εξήγησα πρόσφατα σε ένα άρθρο σχετικά με δομή συμφωνιών διανομής Πώς να διαπραγματευτείτε τις συμφωνίες κοινοπραξίας και να προστατεύσετε τις κατατάξεις αναζήτησηςΤο Syndicating είναι όλη η οργή αυτές τις μέρες. Αλλά ξαφνικά θα μπορούσατε να διαπιστώσετε ότι ο συνεργάτης κοινοπραξίας αναφέρεται ψηλότερα από εσάς στα αποτελέσματα αναζήτησης για μια ιστορία που αρχικά γράψατε! Προστατέψτε τις κατατάξεις αναζήτησης. Διαβάστε περισσότερα ώστε να μην σας βλάψουν (ζητώντας από τους συνεργάτες κοινοπραξίας να απαγορεύσουν την ευρετηρίαση των σελίδων τους στις οποίες είστε κοινοπραξία). Μόλις ο δικός μου συνεργάτης κοινοπραξίας συμφώνησε να το κάνει αυτό, οι σελίδες με διπλό περιεχόμενο από το ιστολόγιό μου εξαφανίστηκαν εντελώς από τις λίστες αναζήτησης.
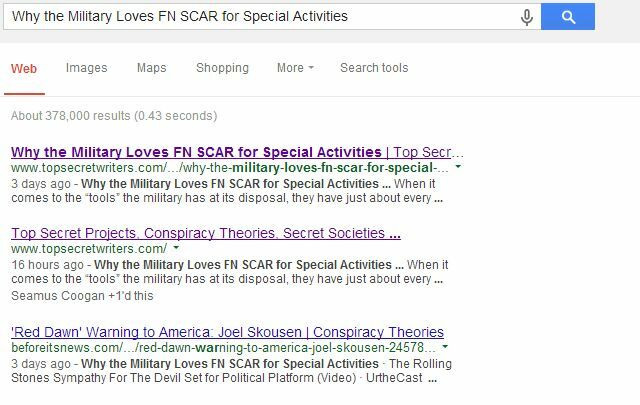
Μόνο ο κύριος ιστότοπος εμφανίζεται στην τρίτη θέση για τη σελίδα όπου παραθέτουν τον τίτλο μας, αλλά το ιστολόγιό μου εμφανίζεται τώρα τόσο στο πρώτο όσο και στο δεύτερο σημείο. κάτι που θα ήταν σχεδόν αδύνατο αν ένας ιστότοπος ανώτερης αρχής άφησε την διπλή σελίδα ευρετηριασμένη.
Αυτό που πολλοί άνθρωποι δεν συνειδητοποιούν είναι ότι αυτό είναι επίσης δυνατό να επιτευχθεί και με το Internet Archive (το Wayback Machine). Ακολουθούν οι γραμμές που πρέπει να προσθέσετε στο αρχείο robots.txt για να συμβεί αυτό.
Χρήστης-πράκτορας: ia_archiver. Απαγόρευση: / sample-κατηγορία /
Σε αυτό το παράδειγμα, λέω στο Αρχείο Διαδικτύου να καταργήσει οτιδήποτε στον υποκατάλογο κατηγορίας δειγμάτων στον ιστότοπό μου από το Wayback Machine. Το αρχείο Διαδικτύου εξηγεί πώς να το κάνετε αυτό στη σελίδα βοήθειας εξαίρεσης. Εδώ εξηγούν επίσης ότι «Το Διαδικτυακό Αρχείο δεν ενδιαφέρεται να προσφέρει πρόσβαση σε ιστοσελίδες ή άλλα έγγραφα στο Διαδίκτυο των οποίων οι συγγραφείς δεν θέλουν το υλικό τους στη συλλογή.»
Αυτό έρχεται σε αντίθεση με την κοινή άποψη ότι οτιδήποτε δημοσιεύεται στο Διαδίκτυο μπαίνει στο αρχείο για όλη την αιωνιότητα. Όχι - οι webmaster που κατέχουν το περιεχόμενο μπορούν συγκεκριμένα να καταργήσουν το περιεχόμενο από το αρχείο χρησιμοποιώντας την προσέγγιση robots.txt.
Καταργήστε μια μεμονωμένη σελίδα με μετα-ετικέτες
Εάν έχετε μόνο μερικές μεμονωμένες σελίδες που θέλετε να καταργήσετε από τα αποτελέσματα αναζήτησης Google, στην πραγματικότητα δεν χρειάζεται να χρησιμοποιήσετε την προσέγγιση robots.txt καθόλου, θα μπορούσατε απλά να προσθέσετε τη σωστή μετα-ετικέτα "ρομπότ" στις μεμονωμένες σελίδες και να πείτε στα ρομπότ να μην ευρετηριάσουν ή να ακολουθήσουν συνδέσμους σε ολόκληρο σελίδα.

Θα μπορούσατε να χρησιμοποιήσετε το παραπάνω "ρομπότ" για να σταματήσετε την ευρετηρίαση της σελίδας από τα ρομπότ ή θα μπορούσατε να πείτε συγκεκριμένα στο ρομπότ Google όχι για ευρετηρίαση, επομένως η σελίδα καταργείται μόνο από τα αποτελέσματα αναζήτησης Google και άλλα ρομπότ αναζήτησης θα μπορούσαν να έχουν πρόσβαση στη σελίδα περιεχόμενο.
Εξαρτάται απόλυτα από εσάς πώς θα θέλατε να διαχειριστείτε τι κάνουν τα ρομπότ με τη σελίδα και εάν η σελίδα παρατίθεται ή όχι. Για λίγες μόνο μεμονωμένες σελίδες, αυτή μπορεί να είναι η καλύτερη προσέγγιση. Για να καταργήσετε έναν ολόκληρο κατάλογο περιεχομένου, ακολουθήστε τη μέθοδο robots.txt.
Η ιδέα της «κατάργησης» περιεχομένου
Αυτό το είδος γυρίζει ολόκληρη την έννοια της «διαγραφής περιεχομένου από το Διαδίκτυο». Τεχνικά, εάν καταργήσετε όλους τους δικούς σας συνδέσμους σε μια σελίδα στον ιστότοπό σας και την αφαιρέσετε από την Αναζήτηση Google και το Internet Archive χρησιμοποιώντας την τεχνική robots.txt, η σελίδα είναι για όλες τις προθέσεις και σκοπούς που «διαγράφονται» από το Διαδίκτυο. Το δροσερό όμως είναι ότι εάν υπάρχουν υπάρχοντες σύνδεσμοι προς τη σελίδα, αυτοί οι σύνδεσμοι θα εξακολουθήσουν να λειτουργούν και δεν θα προκαλέσετε 404 σφάλματα για αυτούς τους επισκέπτες.
Είναι μια πιο «ήπια» προσέγγιση για την κατάργηση περιεχομένου από το Διαδίκτυο χωρίς να αλλοιώνεται πλήρως η υπάρχουσα δημοτικότητα συνδέσμων του ιστότοπού σας σε όλο το Διαδίκτυο. Στο τέλος, πώς διαχειρίζεστε το περιεχόμενο που συλλέγεται από τις μηχανές αναζήτησης και το Αρχείο Διαδικτύου εξαρτάται από εσάς, αλλά πάντα να θυμάστε ότι παρά τα όσα λένε οι άνθρωποι για τη διάρκεια ζωής των πραγμάτων που δημοσιεύονται στο Διαδίκτυο, είναι πραγματικά εντελώς εντός του δικού σας έλεγχος.
Ο Ryan έχει πτυχίο Ηλεκτρολόγου Μηχανικού. Εργάστηκε 13 χρόνια στη μηχανική αυτοματισμού, 5 χρόνια στον τομέα της πληροφορικής και τώρα είναι Μηχανικός εφαρμογών. Πρώην διευθύνων σύμβουλος του MakeUseOf, μίλησε σε εθνικά συνέδρια για την οπτικοποίηση δεδομένων και έχει εμφανιστεί στην εθνική τηλεόραση και ραδιόφωνο.