Διαφήμιση
Στις 27 Ιανουαρίου, η Google ανακοίνωσε ότι το AlphaGo, ένα τεχνητή νοημοσύνη Τι δεν είναι η Τεχνητή ΝοημοσύνηΤα έξυπνα, αισθαντικά ρομπότ πρόκειται να καταλάβουν τον κόσμο; Όχι σήμερα - και ίσως όχι ποτέ. Διαβάστε περισσότερα αναπτύχθηκε από τη θυγατρική της DeepMind, είχε νικήσει τον πρωταθλητή της Ευρώπης Go, Fan Hui σε έναν αγώνα πέντε παιχνιδιών.
Μπορεί να έχετε ακούσει αυτές τις ειδήσεις καθώς γίνεται πρωτοσέλιδα σε όλο τον κόσμο, αλλά γιατί οι άνθρωποι ενδιαφέρονται τόσο πολύ για αυτό; Τι σημαίνουν όλα αυτά; Εάν δεν είστε εξοικειωμένοι με το παιχνίδι του Go ή τη σημασία του για την τεχνητή νοημοσύνη, μπορεί να αισθάνεστε λίγο χαμένοι.
Μην ανησυχείτε, σας καλύπτουμε. Εδώ είναι όλα όσα πρέπει να γνωρίζετε για την ανακάλυψη και πώς επηρεάζει τακτικά άτομα όπως εσείς και εμένα.
Το παιχνίδι του Go: Απλό αλλά πολύπλοκο
Το Go είναι ένα αρχαίο κινεζικό παιχνίδι στρατηγικής όπου δύο παίκτες παλεύουν για να καταλάβουν έδαφος. Στρίψτε με τη σειρά, κάθε παίκτης - ένα λευκό, το άλλο μαύρο - τοποθετεί πέτρες στις διασταυρώσεις ενός πλέγματος 19 x 19. Όταν μια ομάδα πετρών περιβάλλεται εντελώς από τις πέτρες του άλλου παίκτη, "συλλαμβάνονται" και αφαιρούνται από το ταμπλό.
Στο τέλος του παιχνιδιού, κάθε κενό σημείο ανήκει στον παίκτη που το περιβάλλει. Τα σκορ κάθε παίκτη βασίζονται στο πόσα εδάφη κατέχει (δηλ. Πόσο κενό χώρο έχει περιβάλει) συν τον αριθμό των αντιπάλων που τραβήχτηκαν κατά τη διάρκεια του παιχνιδιού.

Ενώ οι περισσότεροι άνθρωποι πιστεύουν πιθανώς ότι το σκάκι είναι ο βασιλιάς των παιχνιδιών στρατηγικής, το Go είναι στην πραγματικότητα πιο περίπλοκο. Σύμφωνα με τη Wikipedia, υπάρχουν 10761 πιθανά παιχνίδια του Go σε σύγκριση με 10120 εκτιμώμενα πιθανά παιχνίδια του Σκακιού.
Αυτή η πολυπλοκότητα, μαζί με μερικούς εσωτερικούς κανόνες και έμφαση στο παιχνίδι από το ένστικτο, καθιστά το Go ένα ιδιαίτερα δύσκολο παιχνίδι για τους υπολογιστές να μάθουν και να παίξουν σε υψηλό επίπεδο.
Ο απίστευτος κόσμος των παιχνιδιών AI που παίζουν παιχνίδια
Στο μεγάλο σχήμα των πραγμάτων, ο σχεδιασμός μιας τεχνητής νοημοσύνης που παίζει ένα παιχνίδι δεν φαίνεται πολύ χρήσιμος επιδίωξη, ειδικά όταν το Watson AI της IBM εργάζεται ήδη για τη βελτίωση της υγειονομικής περίθαλψης, έναν τομέα που χρειάζεται όλη τη βοήθεια που μπορεί παίρνω. Γιατί λοιπόν η Google ξόδεψε τόσες ώρες και δολάρια για να δημιουργήσει μια τεχνητή νοημοσύνη;
Σε ένα επίπεδο, βοηθά τους ερευνητές AI να βρουν τον καλύτερο τρόπο για να διδάξουν τους υπολογιστές να κάνουν πράγματα. Εάν μπορείτε να διδάξετε έναν υπολογιστή για να λύσετε πώς να βρείτε τις καλύτερες κινήσεις σε ένα παιχνίδι Checkers ή Tic-Tac-Toe, θα μπορούσατε να αποκτήσετε μια εικόνα για τη διδασκαλία ενός διαφορετικού υπολογιστή πώς να προτείνουμε ταινίες στο Netflix 4 αλγόριθμοι μηχανικής εκμάθησης που διαμορφώνουν τη ζωή σαςΜπορεί να μην το συνειδητοποιήσετε, αλλά η μηχανική μάθηση είναι ήδη γύρω σας και μπορεί να ασκήσει έναν εκπληκτικό βαθμό επιρροής στη ζωή σας. Δεν με πιστεύεις; Μπορεί να εκπλαγείτε. Διαβάστε περισσότερα , αμέσως μετάφραση ομιλίας ή πρόβλεψη σεισμών.
Πολλές από τις χρήσεις για την τεχνητή νοημοσύνη που έχουμε δει μέχρι στιγμής θα επωφεληθούν από βελτιωμένες δυνατότητες επίλυσης προβλημάτων και εξαγωγής προτύπων, οι οποίες τυχαίνει επίσης να είναι σημαντικές για αποτελεσματικές AI που παίζουν παιχνίδια.
Το Deep Blue, ο πρωταθλητής σκακιού AI, εργάστηκε χρησιμοποιώντας τεράστια τεχνική υπολογιστικής δύναμης και brute force για να αξιολογήσει όλες τις πιθανές επόμενες κινήσεις - έως και 200.000.000 θέσεις ανά δευτερόλεπτο. Και ενώ αυτή η στρατηγική ήταν αρκετά αποτελεσματική για να κερδίσει έναν πρώην Παγκόσμιο Πρωταθλητή Σκακιού, δεν είναι ένας ιδιαίτερα «ανθρώπινος» τρόπος για να παίξετε σκάκι. Απαιτεί επίσης από τους προγραμματιστές να «εξηγήσουν» τους κανόνες του παιχνιδιού στο AI.
Πιο πρόσφατα, αναπτύχθηκε μια διαδικασία που ονομάζεται βαθιά μάθηση, που ουσιαστικά άνοιξε το δρόμο για τους υπολογιστές να διδάσκονται, και αυτό άλλαξε εντελώς το αγώνας για τεχνητή νοημοσύνη Microsoft εναντίον Google - Ποιος ηγείται του αγώνα τεχνητής νοημοσύνης;Οι ερευνητές της τεχνητής νοημοσύνης σημειώνουν απτή πρόοδο και οι άνθρωποι αρχίζουν να μιλούν ξανά σοβαρά για την τεχνητή νοημοσύνη. Οι δύο τιτάνες που πρωτοστατούν στον αγώνα τεχνητής νοημοσύνης είναι η Google και η Microsoft. Διαβάστε περισσότερα .
Με τη βαθιά μάθηση, ένας υπολογιστής μπορεί να εξαγάγει χρήσιμα μοτίβα από δεδομένα - αντί να τους πει από τους προγραμματιστές ποια μοτίβα πρέπει να αναζητήσει - και να χρησιμοποιήσει αυτά τα μοτίβα για να βελτιστοποιήσει τις δικές του αποφάσεις. Εάν η βαθιά μάθηση είναι επιτυχής, μια AI μπορεί ακόμη και να ανακαλύψει μοτίβα που είναι πιο αποτελεσματικά από αυτά που μπορούμε να αναγνωρίσουμε ως ανθρώπους.
Αυτός ο τύπος μάθησης αποδείχθηκε πέρυσι, όταν η εταιρεία ερευνών AI που ανήκει στην Google, DeepMind, αποκάλυψε μια AI που δίδαξε να παίζει 49 διαφορετικά Παιχνίδια Atari Atari Arcade - Παίξτε ρετρό βιντεοπαιχνίδια σε HTML5 [MUO Gaming]Όποιος παίζει βιντεοπαιχνίδια σήμερα, οφείλει ένα τεράστιο χρέος ευγνωμοσύνης στον Atari και στους ιδρυτές και μηχανικούς που εργάστηκαν για την εταιρεία κατά τη διάρκεια των εποχών της. Η Atari ήταν υπεύθυνη για πολλά από τα ... Διαβάστε περισσότερα αφού δοθεί μόνο ακατέργαστη είσοδος. (Μπορείτε να δείτε ότι μαθαίνει να παίζει το Breakout παραπάνω.)
Η διαδικασία είναι ίδια με την εκμάθηση ενός βιντεοπαιχνιδιού χωρίς σεμινάριο ή εξήγηση. Παρακολουθείτε για λίγο, μετά προσπαθείτε να πατάτε τυχαία κουμπιά και, στη συνέχεια, να αρχίζετε να καταλαβαίνετε τα πράγματα, να αναπτύσσετε στρατηγικές και, τελικά, να συνεχίζετε να υπερέχετε.
Και υπερέλαβε. Το DeepMind AI κατέστρεψε εντελώς τους ανθρώπινους αντιπάλους επαγγελματικού επιπέδου σε μερικά από αυτά τα παιχνίδια, όπως το Video Pinball. Τα πήγε πολύ χειρότερα σε άλλα παιχνίδια, συμπεριλαμβανομένης της κας Pac-Man, αλλά είχε πολύ εντυπωσιακό ρεκόρ συνολικά.
AlphaGo: Το επόμενο επίπεδο AI
Ο AlphaGo, ο υπολογιστής που νίκησε τον Fan Hui στο Go, χρησιμοποίησε αυτήν τη στρατηγική βαθιάς μάθησης για να πάει αήττητος σε πέντε αγώνες.
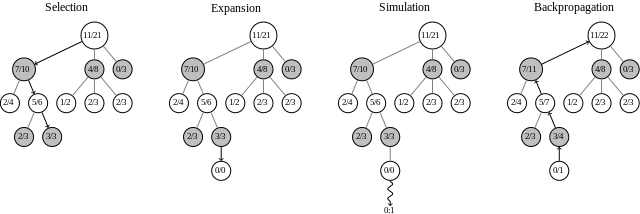
Αντί να χρησιμοποιεί υπολογισμό brute force όπως το Deep Blue, το AlphaGo καθόρισε την επόμενη κίνησή του χρησιμοποιώντας ό, τι είχε μάθει στην εκπαίδευση περιορίστε το εύρος των πιθανώς αποτελεσματικών κινήσεων και, στη συνέχεια, εκτελέστε προσομοιώσεις για να δείτε ποιες κινήσεις ήταν πιο πιθανό να οδηγήσουν σε θετικές αποτελέσματα.
Δύο διαφορετικά νευρωνικά δίκτυα Η τελευταία τεχνολογία υπολογιστών που πρέπει να δείτε για να πιστέψετεΔείτε μερικές από τις τελευταίες τεχνολογίες υπολογιστών που έχουν προγραμματιστεί να μεταμορφώσουν τον κόσμο των ηλεκτρονικών και των υπολογιστών τα επόμενα χρόνια. Διαβάστε περισσότερα , το δίκτυο πολιτικής και το δίκτυο αξιών, συνεργάστηκαν για να αξιολογήσουν τις κινήσεις και να επιλέξουν τις καλύτερες κάθε στροφή.
Λόγω της πολυπλοκότητας του Go, μια προσέγγιση ωμής δύναμης σε όλες τις πιθανές κινήσεις δεν είναι δυνατή όπως είναι στο Σκάκι. Έτσι, η AlphaGo αξιοποίησε τις γνώσεις που απέκτησε κατά τη διάρκεια της προπόνησης, η οποία συνίστατο στην παρακολούθηση 30 εκατομμυρίων κινήσεων από ανθρώπινοι εμπειρογνώμονες, μαθαίνοντας να προβλέπουν τις κινήσεις τους, να κάνουν τις δικές τους στρατηγικές και να παίζουν εναντίον του χιλιάδες φορές.
Χρησιμοποιώντας την ενίσχυση της μάθησης, οι διαδικασίες λήψης αποφάσεων αναπτύχθηκαν και ενισχύθηκαν έως ότου το AlphaGo έγινε το καλύτερο τεχνητό τεχνητό παιχνίδι στον κόσμο. Σε 500 παιχνίδια ενάντια στους πιο εξελιγμένους υπολογιστές Go, κέρδισε 499 από αυτούς - ακόμα και αφού έδινε στα προγράμματα αυτά μια πρώτη κίνηση τεσσάρων κινήσεων.
Και, φυσικά, η AlphaGo νίκησε τον Fan Hui, τον τρέχοντα πρωταθλητή του European Go. Η νίκη επιτεύχθηκε πραγματικά τον Οκτώβριο του 2015, αλλά η ανακοίνωση καθυστέρησε για να συμπέσει με την κυκλοφορία του ερευνητικού εγγράφου της DeepMind στο Φύση. Τον Μάρτιο, η AlphaGo θα αναλάβει τον Lee Sedol, τον πιο κυρίαρχο παίκτη στον κόσμο τα τελευταία δέκα χρόνια.
Εντάξει, τι σημαίνει λοιπόν;
Γιατί αυτό γίνεται πρωτοσέλιδο σε όλο τον κόσμο; Για διάφορους λόγους, στην πραγματικότητα.
Πρώτον, πολλοί άνθρωποι πίστευαν ότι αυτό ήταν αδύνατο με την τρέχουσα τεχνολογία. Οι περισσότερες εκτιμήσεις ανέφεραν ότι μια τεχνητή νοημοσύνη δεν θα νικήσει έναν παγκόσμιο παίκτη Go για τουλάχιστον άλλα δέκα χρόνια. Τα δίκτυα αξίας της AlphaGo μπορούν να αξιολογήσουν οποιοδήποτε παιχνίδι Go που παίζεται αυτήν τη στιγμή και να προβλέψουν έναν πιθανό νικητή, ένα πρόβλημα που λέει η Google είναι "τόσο δύσκολο ήταν πιστεύεται ότι είναι αδύνατο. "

Δεύτερον, το γεγονός ότι χρησιμοποιήθηκε η βαθιά και ανεξάρτητη μάθηση είναι πολύ σημαντικό. Αυτό δείχνει ότι μια τρέχουσα τεχνητή νοημοσύνη μπορεί να συλλέξει δεδομένα, να εξαγάγει μοτίβα, να μάθει να προβλέπει κάτι τέτοιο μοτίβα και τελικά αναπτύσσουν στρατηγικές επίλυσης προβλημάτων που είναι πολύπλοκες και αρκετά αποτελεσματικές για να ξεπεράσουν το α άνθρωπος παγκόσμιας κλάσης.
Και ενώ η νίκη στο Go δεν πρόκειται να αλλάξει τον κόσμο, το γεγονός ότι ένας υπολογιστής μπόρεσε να βρει αυτό το επίπεδο στρατηγικής χρησιμοποιώντας τους δικούς του αλγόριθμους μάθησης είναι πολύ εντυπωσιακό.
Είναι αυτή η βαθιά μάθηση που οι ερευνητές της AI έχουν πραγματικά ενθουσιαστεί για το AlphaGo. Πολλοί πιστεύουν ότι η ανεξάρτητη μάθηση είναι το πρώτο βήμα προς τη δημιουργία ισχυρή τεχνητή νοημοσύνη. Ένα ισχυρό AI αναφέρεται σε έναν υπολογιστή που μπορεί να επιλύσει πνευματικά καθήκοντα ισοδύναμα με τον άνθρωπο (ο οποίος είναι απίστευτα δύσκολος, κυρίως λόγω της πολυπλοκότητας και της αποτελεσματικότητας του ανθρώπινου εγκεφάλου). Αυτό είναι το είδος της AI που βλέπετε πολλές ταινίες επιστημονικής φαντασίας Προσοχή, Διαδίκτυο! Οι καλύτερες ταινίες για την τεχνητή νοημοσύνηΤο Χόλιγουντ έχει κυκλοφορήσει πολλές υπέροχες ταινίες που εξερευνούν τα θέματα της τεχνητής νοημοσύνης όλα αυτά τα χρόνια, και εδώ είναι 10 από τις καλύτερες ταινίες για την τεχνητή νοημοσύνη. Σας προτείνουμε να μετακινήσετε το Heaven and Earth σε ... Διαβάστε περισσότερα .

Γι 'αυτό το λόγο η δημιουργία AI που μπορούν να συμπεριφέρονται με ανθρώπινους τρόπους είναι τόσο μεγάλη υπόθεση. Η εξαγωγή προτύπων και η ανάπτυξη στρατηγικών είναι κάτι που κάνουμε συνεχώς και δεν χρησιμοποιούμε μεθόδους ωμής βίας κατά τη λήψη αποφάσεων.
Είναι πολύ δύσκολο να κάνεις έναν υπολογιστή για να το κάνεις αυτό χωρίς πολλή καθοδήγηση, αλλά χάρη στο AlphaGo, τώρα γνωρίζουμε ότι η ισχυρή τεχνητή νοημοσύνη δεν είναι απλώς δυνατή, αλλά πλησιέστερα από ό, τι νομίζαμε.
Φυσικά, το Go-playing AI απέχει πολύ πολύ από ένα γενικά έξυπνο AI. Κάνει μόνο ένα πράγμα, το οποίο είναι τόσο απλό όσο μπορεί να πάρει μια τεχνητή νοημοσύνη - ακόμα και το AI που παίζει το Atari μπορεί να παίξει 49 διαφορετικά παιχνίδια Τα μελλοντικά βιντεοπαιχνίδια θα σας φρικάρουν σοβαράΤο Videogame AI δεν είναι τόσο μεγάλο - ακόμα. Ωστόσο, με τις πρόσφατες τεχνολογικές εξελίξεις, αυτό μπορεί σύντομα να αλλάξει. Διαβάστε περισσότερα - αλλά η αποτελεσματική ανεξάρτητη μάθηση του AlphaGo θα μπορούσε να είναι το πρώτο βήμα προς μια σημαντική αλλαγή παραδείγματος στην AI.
Τι νομίζετε?
Δεν υπάρχει αμφιβολία ότι η νίκη του AlphaGo έναντι του Fan Hui είναι σημαντική, αλλά αν αξίζει ή όχι παγκόσμια πρωτοσέλιδα είναι προς συζήτηση.
Πιστεύετε ότι είναι μεγάλη υπόθεση; Είμαστε ένα βήμα πιο κοντά στο αποκάλυψη ρομπότ Microsoft, Artificial Intelligence και The Robot ApocalypseΗ Microsoft δίνει μια σειρά από αυτόνομα ρομπότ μια σοβαρή εμφάνιση. Είναι αυτή η αρχή του τέλους για τους ανθρώπους, ή απλά ένα άλλο βήμα προς τα εμπρός στην ώθηση για ασφαλή τεχνητή νοημοσύνη; Διαβάστε περισσότερα ? Ή δεν εντυπωσιάζεστε με μια τεχνητή νοημοσύνη που μπορεί να παίξει μόνο ένα παιχνίδι; Μοιραστείτε τις σκέψεις σας παρακάτω και ας μιλήσουμε για αυτό.
Συντελεστές εικόνας: πάμε στο παιχνίδι από vvoe μέσω του Shutterstock, Tatiana Belova μέσω του Shutterstock.com, Mciura μέσω Wikimedia Commons, Zerbor μέσω του Shutterstock.com
Ο Dann είναι σύμβουλος στρατηγικής περιεχομένου και μάρκετινγκ που βοηθά τις εταιρείες να δημιουργήσουν ζήτηση και δυνητικούς πελάτες. Επίσης, δημοσιεύει ιστολόγια σχετικά με τη στρατηγική και το μάρκετινγκ περιεχομένου στο dannalbright.com.